Boosting ViT-based MRI Reconstruction from the Perspectives of Frequency Modulation, Spatial Purification, and Scale Diversification
Yucong Meng, Zhiwei Yang, Yonghong Shi†, Zhijian Song†
Association for the Advancement of Artificial Intelligence (AAAI 2025 Oral)
Abstract
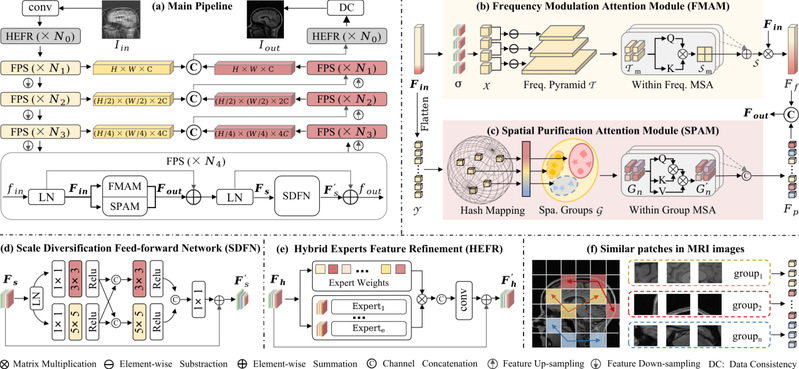
The accelerated MRI reconstruction process presents a challenging ill-posed inverse problem due to the extensive under-sampling in k-space. Recently, Vision Transformers (ViTs) have become the mainstream for this task, demonstrating substantial performance improvements. However, there are still three significant issues remain unaddressed: (1) ViTs struggle to capture high-frequency components of images, limiting their ability to detect local textures and edge information, thereby impeding MRI restoration; (2) Previous methods calculate multi-head self-attention (MSA) among both related and unrelated tokens in content, introducing noise and significantly increasing computational burden; (3) The naive feed-forward network in ViTs cannot model the multi-scale information that is important for image restoration. In this paper, we propose FPS-Former, a powerful ViT-based framework, to address these issues from the perspectives of frequency modulation, spatial purification, and scale diversification. Specifically, for issue (1), we introduce a frequency modulation attention module to enhance the self-attention map by adaptively re-calibrating the frequency information in a Laplacian pyramid. For issue (2), we customize a spatial purification attention module to capture interactions among closely related tokens, thereby reducing redundant or irrelevant feature representations. For issue (3), we propose an efficient feed-forward network based on a hybrid-scale fusion strategy. Comprehensive experiments conducted on three public datasets show that our FPS-Former outperforms state-of-the-art methods while requiring lower computational costs.