An Empirical Study on the Fairness of Foundation Models for Multi-Organ Image Segmentation
Qing Li*, Yizhe Zhang*, Yan Li, Jun Lyu, Meng Liu, Longyu Sun, Mengting Sun, Qirong Li, Wenyue Mao, Xinran Wu, Yajing Zhang, Yinghua Chu, Shuo Wang†, Chengyan Wang†
International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI2024)
Abstract
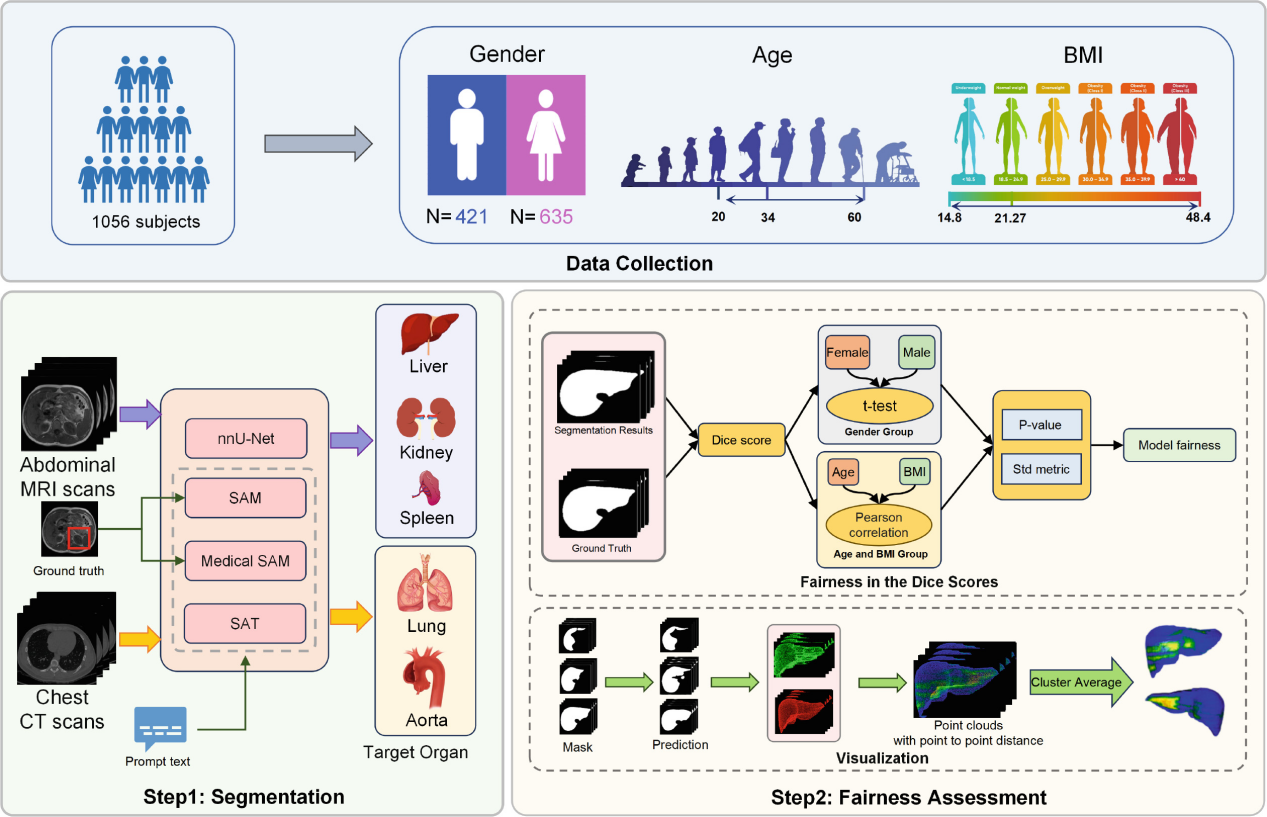
The segmentation foundation model, e.g., Segment Anything Model (SAM), has attracted increasing interest in the medical image community. Early pioneering studies primarily concentrated on assessing and improving SAM’s performance from the perspectives of overall accuracy and efficiency, yet little attention was given to the fairness considerations. This oversight raises questions about the potential for performance biases that could mirror those found in task-specific deep learning models like nnU-Net. In this paper, we explored the fairness dilemma concerning large segmentation foundation models. We prospectively curate a benchmark dataset of 3D MRI and CT scans of the organs including liver, kidney, spleen, lung and aorta from a total of 1056 healthy subjects with expert segmentations. Crucially, we document demographic details such as gender, age, and body mass index (BMI) for each subject to facilitate a nuanced fairness analysis. We test state-of-the-art foundation models for medical image segmentation, including the original SAM, medical SAM and Segment Anything in medical scenarios, driven by Text prompts(SAT-Nano) models, to evaluate segmentation efficacy across different demographic groups and identify disparities. Our comprehensive analysis, which accounts for various confounding factors, reveals significant fairness concerns within these foundational models. Moreover, our findings highlight not only disparities in overall segmentation metrics, such as the Dice Similarity Coefficient but also significant variations in the spatial distribution of segmentation errors, offering empirical evidence of the nuanced challenges in ensuring fairness in medical image segmentation.