Image synthesis-based multi-modal image registration framework by using deep fully convolutional networks
Xueli Liu, Dongsheng Jiang, Manning Wang, Zhijian Song
(2018)Medical & Biological Engineering & Computing
Abstract:
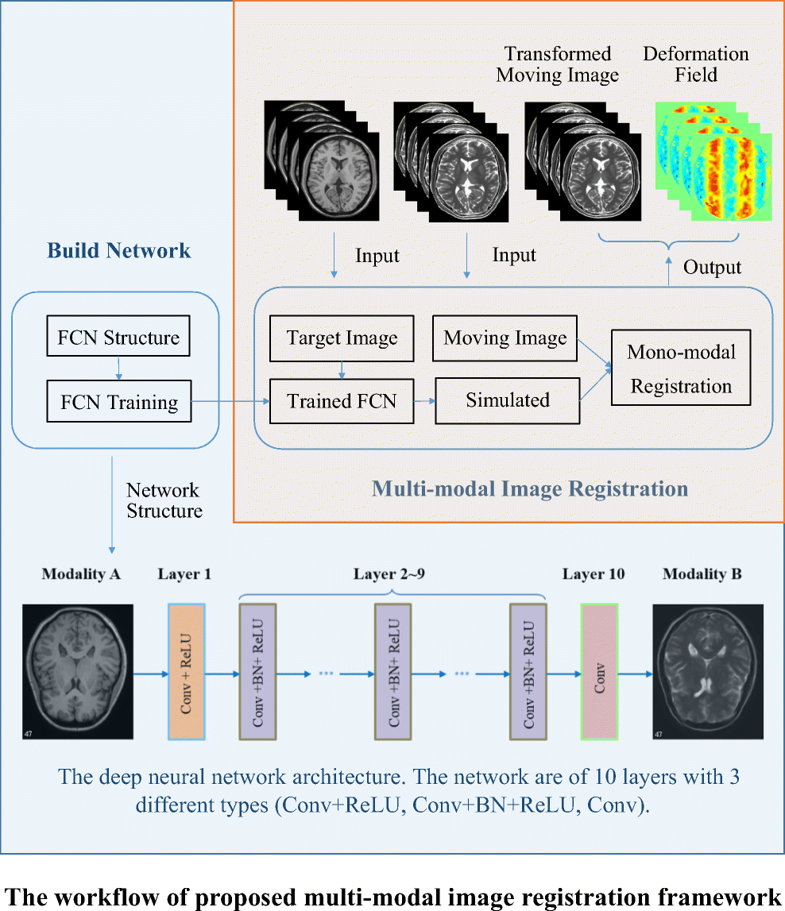
Multi-modal image registration has significant meanings in clinical diagnosis, treatment planning, and image-guided surgery. Since different modalities exhibit different characteristics, finding a fast and accurate correspondence between images of different modalities is still a challenge. In this paper, we propose an image synthesis-based multi-modal registration framework. Image synthesis is performed by a ten-layer fully convolutional network (FCN). The network is composed of 10 convolutional layers combined with batch normalization (BN) and rectified linear unit (ReLU), which can be trained to learn an end-to-end mapping from one modality to the other. After the cross-modality image synthesis, multi-modal registration can be transformed into mono-modal registration. The mono-modal registration can be solved by methods with lower computational complexity, such as sum of squared differences (SSD). We tested our method in T1-weighted vs T2-weighted, T1-weighted vs PD, and T2-weighted vs PD image registrations with BrainWeb phantom data and IXI real patients’ data. The result shows that our framework can achieve higher registration accuracy than the state-of-the-art multi-modal image registration methods, such as local mutual information (LMI) and α-mutual information (α-MI). The average registration errors of our method in experiment with IXI real patients’ data were 1.19, 2.23, and 1.57 compared to 1.53, 2.60, and 2.36 of LMI and 1.34, 2.39, and 1.76 of α-MI in T2-weighted vs PD, T1-weighted vs PD, and T1-weighted vs T2-weighted image registration, respectively. In this paper, we propose an image synthesis-based multi-modal image registration framework. A deep FCN model is developed to perform image synthesis for this framework, which can capture the complex nonlinear relationship between different modalities and discover complex structural representations automatically by a large number of trainable mapping and parameters and perform accurate image synthesis. The framework combined with the deep FCN model and mono-modal registration methods (SSD) can achieve fast and robust results in multi-modal medical image registration.