Vector-Quantization-Driven Active Learning for Efficient Multi-Modal Medical Segmentation with Cross-Modal Assistance
Xiaofei Du, Haoran Wang, Manning Wang†, Zhijian Song†
International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI2025)
Abstract
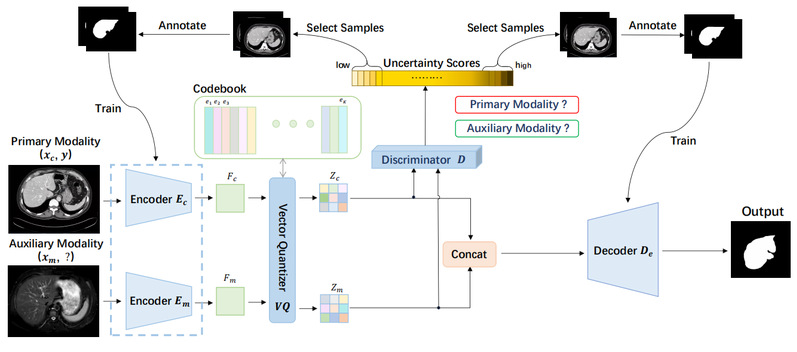
Multi-modal medical image segmentation leverages complementary information across different modalities to enhance diagnostic accuracy, but faces two critical challenges: the requirement for extensive paired annotations and the difficulty in capturing complex inter-modality relationships. While Active Learning (AL) can reduce annotation burden through strategic sample selection, conventional methods suffer from unreliable uncertainty quantification. Meanwhile, Vector Quantization (VQ) offers a mechanism for encoding inter-modality relationships, yet existing implementations struggle with codebook misalignment across modalities. To address these limitations, we propose a novel Vector Quantization-Bimodal Entropy-Guided Active Learning (VQ-BEGAL) framework that employs a dual-encoder architecture with VQ to discretize continuous features into distinct codewords, effectively preserving modality-specific information while mitigating feature co-linearity. Unlike conventional AL methods that separate sample selection from model training, our approach integrates feature-level uncertainty estimation from cross-modal discriminator outputs into the training process-strategically allocating samples with different uncertainty characteristics to optimize specific network components, enhancing both feature extraction stability and decoder robustness. Experiments on benchmark datasets demonstrate that our approach achieves state-of-the-art performance while requiring significantly fewer annotations, making it particularly valuable for real-world clinical applications where labeled data is scarce.