MDAL: Modality-difference-based active learning for multimodal medical image analysis via contrastive learning and pointwise mutual information
Computerized Medical Imaging and Graphics (IF=5.4)
Abstract
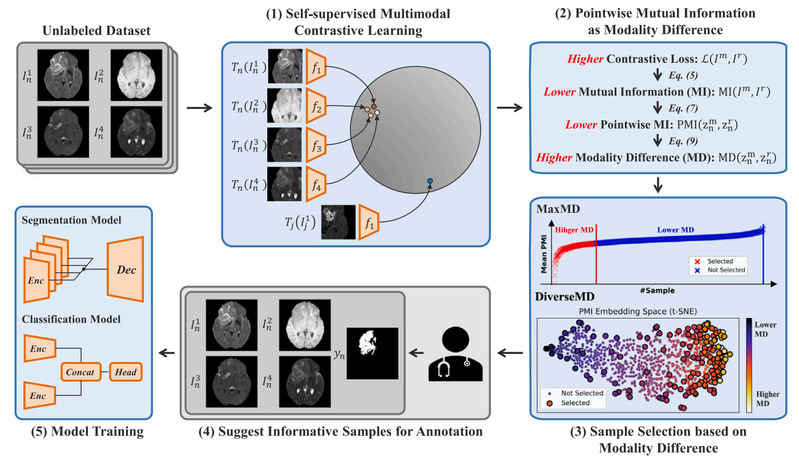
Multimodal medical images reveal different characteristics of the same anatomy or lesion, offering significant clinical value. Deep learning has achieved widespread success in medical image analysis with large-scale labeled datasets. However, annotating medical images is expensive and labor-intensive for doctors, and the variations between different modalities further increase the annotation cost for multimodal images. This study aims to minimize the annotation cost for multimodal medical image analysis. We proposes a novel active learning framework MDAL based on modality differences for multimodal medical images. MDAL quantifies the sample-wise modality differences through pointwise mutual information estimated by multimodal contrastive learning. We hypothesize that samples with larger modality differences are more informative for annotation and further propose two sampling strategies based on these differences: MaxMD and DiverseMD. Moreover, MDAL could select informative samples in one shot without initial labeled data. We evaluated MDAL on public brain glioma and meningioma segmentation datasets and an in-house ovarian cancer classification dataset. MDAL outperforms other advanced active learning competitors. Besides, when using only 20%, 20%, and 15% of labeled samples in these datasets, MDAL reaches 99.6%, 99.9%, and 99.3% of the performance of supervised training with full labeled dataset, respectively. The results show that our proposed MDAL could significantly reduce the annotation cost for multimodal medical image analysis. We expect MDAL could be further extended to other multimodal medical data for lower annotation costs.